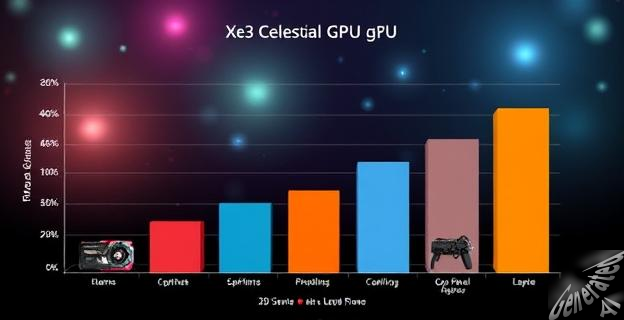
Intel Panther Lake mejora su rendimiento gracias a unos parches para su GPU Xe3 Celestial: +2,4% de media, hasta +18% en algunos juegos
Intel ha mejorado el rendimiento de su GPU Xe3 Celestial en la arquitectura Panther Lake gracias a una serie de parches. Estos parches han mejorado el rendimiento en juegos como NBA 2K23, Baldur’s Gate 3, Ghostrunner 2, Space Engineers y Hogwarts Legacy, con ganancias de hasta un 18% en FPS. El desarrollador de Intel, Francisco Jerez, ha explicado que la clave de estas optimizaciones está en equilibrar el uso de registros y el paralelismo de subprocesos. Las pruebas han mostrado un aumento de rendimiento del 2,4% de media, aunque con matices según el título que se mire. Por ejemplo, en la primera gráfica, se aprecia una tendencia clara de mejora en juegos como Borderlands 3, Cyberpunk 2077, Hitman 3 y Hogwarts Legacy, con ganancias que van del 8% al 30%. Intel tiene todavía algo más de dos meses para mejorar los datos antes del lanzamiento de la arquitectura Panther Lake.
...promete mucho con su título, pero en realidad, la mejora del 2,4% de media es más bien modesta. Sin embargo, es interesante ver cómo Intel está trabajando para mejorar el rendimiento de su GPU. La pregunta es, ¿será suficiente para competir con los gigantes de la industria? Solo el tiempo lo dirá. Mientras tanto, podemos disfrutar de los gráficos de barras y soñar con un futuro donde las GPUs de Intel sean las mejores.










